I recently got back to Android because I came across an article on installing Ubuntu "natively" on Android without systemd via Termux and proot. I will link relevant articles as I update this post. After I installed Ubuntu via proot, I searched for ways to get a GUI running. This can be done via VNC Server. Again, I will link relevant articles later. Then, I looked for ways to get VS Code running and found that most guides propose installing code-server and then accessing Code via a browser, which has some limitations with extensions. I would propose using vscode.dev instead if you generally have a good network connection on your phone. Because I had a gui running from step 2, I installed VS Code as you would normally on Ubuntu (from a .deb file or using the tar.gz file available for download for arm64 on the VS code website. I realised that I could not install .deb files on a stripped down Ubuntu environment (it worked when I installed ubuntu-desktop instead of gnome deskto...
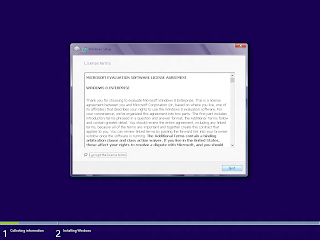
OS: Windows 8 RTM 90 day Evaluation 32bit PC: Acer Aspire One AOA 150 CPU: Atom N270 Graphics: Mobile Intel 945 Graphics Chipset with 256 MB memory HDD: 500gb 7200rpm SATA(custom) Screen Resolution: 1024x600 Installation: Installation was launched from within Windows 8 Release Preview. However, since upgrading from Windows 8 Release Preview to RTM is not supported, a clean installation was done Installing Windows 8 : License Agreement Select Upgrade vs Custom Install Select Partition Windows 8 Installation Windows 8 installation restarts the computer a couple of times. After installing devices, installation prompts you to select express settings vs custom settings. These settings include the new "Do Not Track" feature in Internet Explorer 10, which is enabled by default if you select Express Settings and is shown clearly. It also includes a "Share information with Apps including your name, picture and location" setting. This is to pe...
Update November 1st 2012: Windows 8 on Acer Aspire AOA 150 Update: October 31st 2012 Since posting this article about over a year ago, the said AOA 150 is still alive, although with some changes. I have added a 500gb 7200 rpm HDD(ST9500420ASG) to the netbook. The netbook now runs a Windows 8 Release Preview with Ubuntu 12.10 as the main OS. Windows 8 Release Preview apparently runs faster than Developer Preview. I might buy an upgrade license to Windows 8 pro, but with a resolution of 1024x600 and metro(windows 8) apps not working, I don't see much point. But I do need something to run my Nokia Music on... Other updates on Windows 8 1. License types available for Windows 8: a. Upgrade License - $39.99 till January 31 2013 b. OEM License (The license which vendors will use when they bundle Windows 8 with your new PC) c. System Builder License (Similar to the OEM license, but you can purchase this to build your own PC. Single PC/Virtual Environment u...